FR
“I wasted a whole week trying to convert an Epub file onto text, but you should not”
I will be working with my EBook, you can get yours and get its path if you’re running locally If your working on Collab it will be easier just upload it and get its path.
I will be working with the following packages, you better pip install them before starting
!pip install ebooklib
!pip install BeautifulSoup4
I will be getting a path of the epub file, then I will turn it to a list of HTML, each HTML is a chapter (I believe).
I believe it’s XHTML, but I’ve put its content in a file.txt, and I was able to open it in the browser and view the content, therefore I will keep calling it HTML during this project to simplify, “but it is NOT”.
I used the ebooklib library to extract the HTML out of the epub file using the “item.get_content()”
import ebooklib
from ebooklib import epub
def epub2thtml(epub_path):
book = epub.read_epub(epub_path)
chapters = []
for item in book.get_items():
if item.get_type() == ebooklib.ITEM_DOCUMENT:
chapters.append(item.get_content())
return chapters
Ok if you visualize the output, it is full of HTML brackets. My text is to be fed to a machine to learn from it, I don’t want it to get confused by these brackets,
“I, myself was confused with these HTML brackets”
So I will be using a very friendly framework, BeautifulSoup that is basically used to get content from the web and scrap it. I don’t have content on the web, but I do have its format! therefore, It should be just good :)
To understand furthermore the use of beautiful soup check this article
from bs4 import BeautifulSoup
blacklist = ['[document]', 'noscript', 'header', 'html', 'meta', 'head','input', 'script']
# there may be more elements you don't want, such as "style", etc.
def chap2text(chap):
output = ''
soup = BeautifulSoup(chap, 'html.parser')
text = soup.find_all(text=True)
for t in text:
if t.parent.name not in blacklist:
output += '{} '.format(t)
return output
def thtml2ttext(thtml):
Output = []
for html in thtml:
text = chap2text(html)
Output.append(text)
return Output
def epub2text(epub_path):
chapters = epub2thtml(epub_path)
ttext = thtml2ttext(chapters)
return ttext
now the process finished let us see the result
out=epub2text('/content/[Franz_Kafka,_John_Updike]_The_Complete_Stories(z-lib.org).epub')
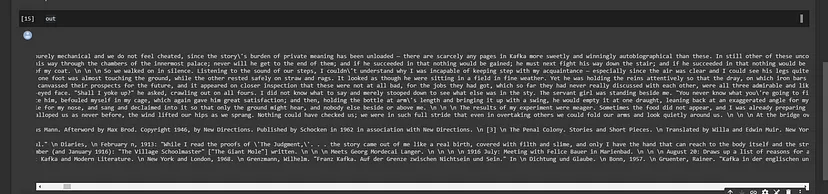
Ok I have some “\n” noise but I need it to separate content, the first 2 lines mean nothing basically, but the rest is rich of content. so I might call it a Day.
Feel free to ask me if you didn't understand a line, and feel free to contribute to my Github repository, that contains all the base code.
Thank you for your time, leave a couple of claps if you liked it, comment if you think it can be improved.
This was my first article on medium so I hope you liked it.